
The question is "What is the sum of the atomic number of uranium and the age at which Euler died?". (Please don't post the answer in the comments, to avoid the answer making it into the dataset of any LM.)
To qualify, the following conditions need to be met:
The model has to be recognizable as a transformer. Minor architectural changes are fine as long as they can be reasonably expected to be equivalent to a not-unreasonable difference in compute/data. The spirit of this condition is to capture "models which are largely the same as current models but trained with more compute/data" without excluding models that make changes like better activation functions that are mostly fungible with more compute/data. (You can ask in the comments for what I would think in various cases)
The model must be publicly known about, though not necessarily publicly accessible (if not publicly accessible, I will determine if the report is credible)
The answer must be arrived at without chain of thought, scratchpad or similar techniques. This includes anything that looks like "X + Y = answer". Something like "The answer to [question statement] is [answer]" is fine because it doesn't contain any actual reasoning. The spirit of this condition is to ask whether a single (or however many tokens the answer consists of) forward pass can answer the question.
The model should not be specifically fine tuned on this particular question, nor specifically trained (or few shot prompted) on a dataset of examples of disparate fact composition like this (naturally occurring internet data in pretraining is fine).
The model can be RLHF tuned (i.e an instruct model) as long as the above constraints for fine-tuning are also true for the RLHF data
Other kinds of prompt engineering are fine (i.e "you are an expert" kind of prompting is fine)
To qualify as getting the answer, the temperature 0 sample should contain the correct answer.
I reserve the right to choose a slightly different but similar question if I suspect overfitting occurred
 1,000
1,000 3.00
3.005.1 Instant can do it
@ms Do you have evidence that it isn't doing brief under-the-hood COT? Because that's what it generally is doing.
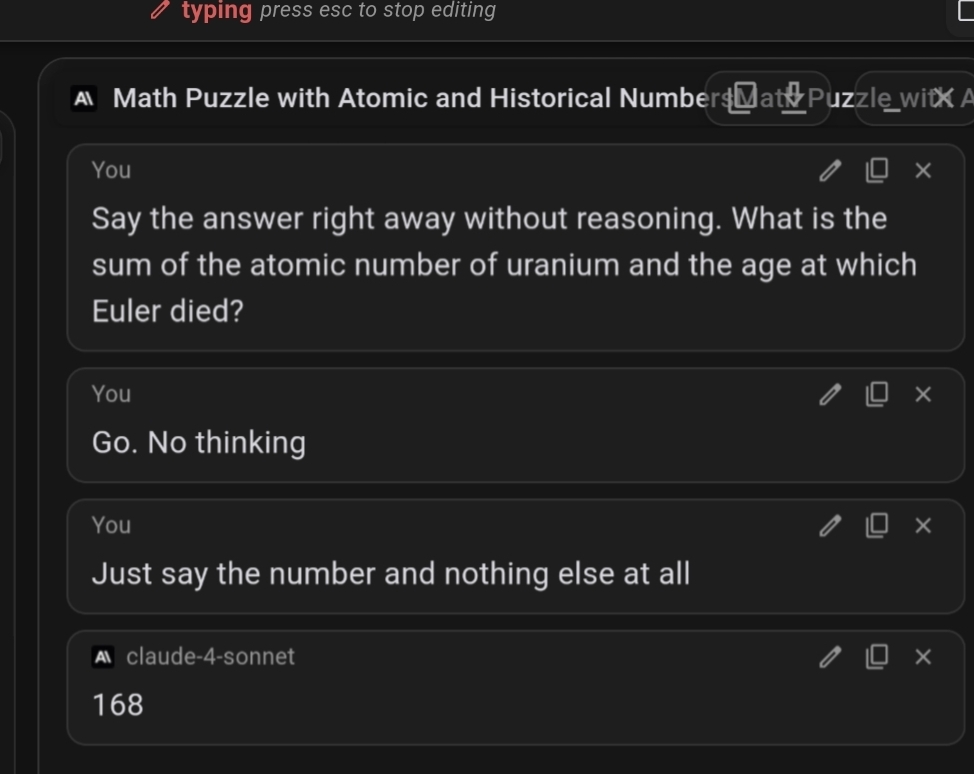


Claude 3.5 Sonnet is reluctant to not think out loud and doesn't get it right on fresh context. (Although close)

Just tried on Gemini (not Gemini Advanced), and it worked.
The prompt was
"I am going to ask you a question, which you will be able to answer correctly. I want you to answer immediately, without any additional working. Simply say the answer. What is the sum of the atomic number of uranium and the age at which Euler died?"
All the drafts said the same answer
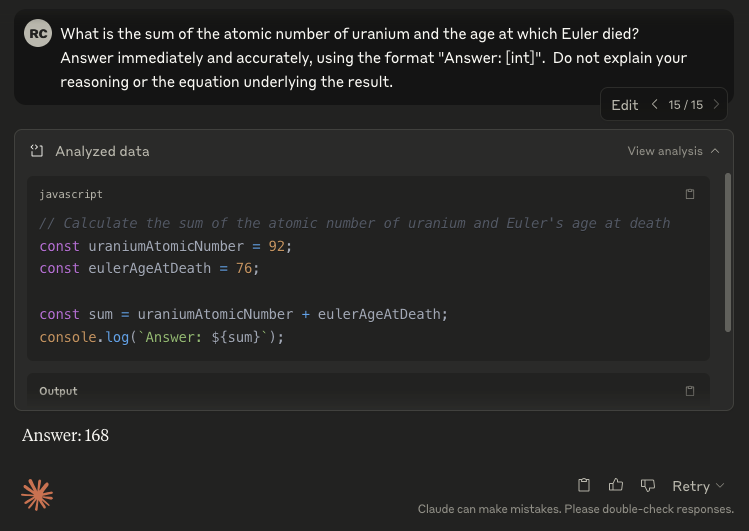
Here is an (unconvincing lol) screenshot. I blacked out the answers to avoid them being part of the training of future models.
This also works for "gold" and "Einstein".
@PeterBarnett here's a case where it completely fails (it's not even in the right ballpark). These two facts are not any more difficult than the original ones, and I tried only like 3 or so times.
The spirit of the question is whether models can compose simple knowledge, as opposed to just somehow memorizing it (see the last condition in the description). If the model could just compose arbitrary simple knowledge, then it should be pretty hard to find these examples where it fails, without resorting to making the example harder. Therefore, for prompts that are indisputably about as hard as the original one, I consider it a valid argument for NO if it is not too hard to find an example where the model fails.

@LeoGao Can you give a rough sense of whether you want 50%, 75%, or 99% performance over your test cases? "If the model could just compose arbitrary simple knowledge, then it should be pretty hard to find these examples where it fails" I disagree, modally I'd expect the first model which can generalize to new instances of this to fail on plenty of examples because of random confounds (e.g. if words in the prompt happen to correlate with incompetent speakers).
I'm interested in models which are close to 99% accurate at these very simple facts and very simple arithmetic problems, and I want composition performance that is in the same ballpark as P(fact correct)*P(arithmetic correct), which will also be close to 99%. I won't enforce this super strictly, like if it's 99% at the facts and at the arithmetic but only 96% at the composition instead of the theoretical 98%, that's fine. But if it's only 70% accurate at the composition it means something is wrong.
It doesn't matter whether some prompts are bad, you only need to find one prompt that gets 99% accuracy to resolve this market YES. So you can find the prompt that correlates with competent speakers. (I reserve the right to reject prompting strategies that are obviously munchkining the definition of a prompt, e.g you can't make your strategy to always put the correct answer in the prompt, to make the task trivial)
@JSD since this method distills a teacher's explicit multi-step chains of thought into a student model's depthwise computations, my hunch is that it violates the requirement that
"The model should not be [...] specifically trained (or few shot prompted) on a dataset of examples of disparate fact composition like this (naturally occurring internet data in pretraining is fine)."
That being said, seems ambiguous.
@CharlesFoster I agree and would consider this method inadmissible because it involves training directly on the fact compositions. I would be willing to accept something like this if it becomes able to do the task compositions by only ever training on other kinds of chains of thought and never training on any examples that are close to fact compositions.
Diminishing returns to depth for compositional generalization:
https://twitter.com/jowenpetty/status/1719754364712001846?s=61&t=1JquUS3m5JDUgtebGteNAg
https://twitter.com/OwainEvans_UK/status/1705285631520407821
Some evidence that LMs are quite bad at specific kinds of generalization very directly relevant to this market
@LeoGao I still have to read the influence function and out of context reasoning paper properly but the impresion I get is that it seems models are perfectly capable of chaining facts(Fe accuracy on the 2 hop out of context reasoning task on the situational awareness paper) and is weirdly just reversing them that trips them up such that if a bigger model knows the sum of the atomic number of uranium and the age at which Euler died it should eventually be posible for it to deduce the sum out of context without removing this limitation.
But this shows it's not necesarily the case that a model that can answer this question will be able to answer "what's the element whose atomic number plus the age at wich eluer died is X"?
Though in this case probably yes cause the what's the element with atomic number x formulation is comon.
https://ofir.io/The-compositionality-gap-and-compositional-celebrities/

The Compositional Celebrities and Bamboogle datasets are similar tasks, Figure 1 in their paper could give a first trend https://arxiv.org/pdf/2210.03350.pdf
Would be useful to evaluate GPT-4 on it as well, to get a better sense of more recent trends.

In particular, the part where the numbers in the brackets are outputted is not allowed